😤 CPU로는 한계가 왔다#
트레이딩 봇 MOON SEEKER를 개발하면서 슈퍼트렌드 전략의 최적 파라미터를 찾아야 했어요. 문제는 테스트해야 할 조합이 2만 개라는 거였죠.
200개 알트코인 × 다양한 파라미터 조합 = 2만 개의 백테스팅
서버의 E3-1230 V2 CPU로 순차 처리하면 며칠이 걸릴 판이었어요. GPU 병렬 처리가 절실했습니다.
🎯 GPU 선정의 조건#
마냥 좋은 GPU를 살 수는 없었어요. 현실적인 제약 조건이 있었거든요.
| 조건 | 이유 |
|---|---|
| VRAM 8GB 이상 | 2만 개 조합을 메모리에 올려야 함 |
| 8핀 케이블 1개 | 파워 케이블이 하나뿐 |
| 적당한 가격 | 와이프 설득 가능한 선 |
| 낮은 전력 | 24시간 돌릴 거라 전기세 중요 |
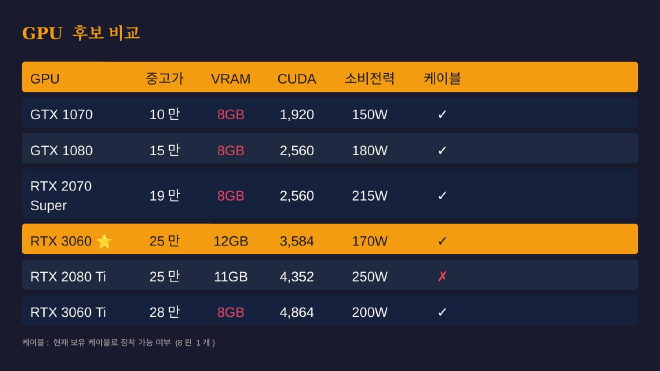
📊 GPU 후보 비교#
중고 시장을 뒤져서 후보군을 정리했어요.
| GPU | 중고가 | VRAM | 소비전력 | 케이블 |
|---|---|---|---|---|
| GTX 1070 | 10만 | 8GB | 150W | ✓ |
| GTX 1080 | 15만 | 8GB | 180W | ✓ |
| RTX 2070 Super | 19만 | 8GB | 215W | ✓ |
| RTX 3060 | 25만 | 12GB | 170W | ✓ |
| RTX 2080 Ti | 25만 | 11GB | 250W | ✗ (8핀x2) |
| RTX 3060 Ti | 28만 | 8GB | 200W | ✓ |
RTX 3060이 눈에 들어왔어요. 같은 가격대의 2080 Ti보다 VRAM이 1GB 더 많고, 전력은 80W나 적게 먹더라고요. 케이블도 8핀 1개면 되고요.
👊 보스전: 와이프 설득#
GPU를 사려면 넘어야 할 산이 있었어요. 바로 와이프 설득이라는 보스전이었죠.
“아직 수익도 안 나는데 25만원짜리 그래픽카드를 왜 사?”
논리적으로 접근하기로 했어요. PPT를 만들었습니다. 진짜로요 ㅋㅋㅋ

PPT 구성은 이랬어요.
- 현재 상황 (봇 개발 완료, 수익화 전)
- 문제점 (2만 개 조합, CPU 한계)
- 해결책 (GPU 병렬 처리)
- GPU 비교표 (6개 모델 분석)
- 선정 이유 (12GB + 170W + 25만)
- 전기세 분석 (월 18,000원)
- 투자 요청 (250,000원)
전기세 비교도 넣었어요. RTX 3060은 월 18,000원, RTX 2080 Ti는 월 27,000원. 매달 9,000원 절약이라는 논리였죠.
결과: 설득 성공! 💪
🎉 26만원에 낙찰#
당근마켓에서 RTX 3060 12GB를 26만원에 구했어요. 목표가 25만원이었는데 1만원 오버했지만, 상태 좋은 매물이라 만족합니다.
😱 반전: RAM이 터진다#
GPU 장착하고 백테스팅을 돌렸는데… 컴퓨터가 죽어버렸어요.
RAM 16GB + Swap 8GB = 24GB
그래도 OOM → 커널 패닉 → 사망
원인을 찾아보니 H61 메인보드의 한계였어요.
| 칩셋 | 최대 RAM |
|---|---|
| H61 | 16GB |
| B75 | 32GB |
| Z77 | 32GB |
H61은 DDR3 16GB가 맥스더라고요. 아무리 GPU가 좋아도 RAM이 부족하면 소용없었던 거죠 😭
💡 해결: 프리컴퓨트 데이터를 SSD로#
Swap 늘리는 건 임시방편이었어요. 근본적인 해결책을 찾았습니다.
프리컴퓨트한 데이터를 RAM에 다 올리지 않고 SSD에 파일로 캐싱하는 방식이었죠.
# 이전: 전부 RAM에 올림 → OOM 💀
all_data = precompute_all_symbols()
# 이후: SSD에 파일로 캐싱
for symbol in symbols:
result = precompute(symbol)
save_to_disk(f"cache/{symbol}.pkl")
# 필요할 때만 로드
data = load_from_disk(f"cache/{symbol}.pkl")
200개 심볼 데이터를 한 번에 RAM에 올릴 필요가 없어졌어요. 필요한 것만 그때그때 로드하면 되니까요.
SSD가 RAM보다 느리긴 하지만, OOM으로 죽는 것보다 100배 나아요. 결과적으로 16GB RAM으로도 백테스팅을 돌릴 수 있게 됐습니다. 💪
🎁 보너스: 로컬 LLM도 가능#
백테스팅 외에도 RTX 3060 12GB로 할 수 있는 게 있었어요. 바로 로컬 LLM이죠!
2026년 기준 로컬 LLM 트렌드가 엄청 발전했어요. RTX 3060 12GB면 꽤 쓸만한 모델들을 돌릴 수 있습니다.
| 모델 | VRAM | 용도 | 추천도 |
|---|---|---|---|
| DeepSeek-R1:8b | ~6GB | 추론/수학 | ⭐⭐⭐⭐⭐ |
| Qwen 2.5:14b Q4 | ~10GB | 범용/다국어 | ⭐⭐⭐⭐⭐ |
| Qwen 2.5-Coder:7b | ~5GB | 코딩 | ⭐⭐⭐⭐⭐ |
| Llama 3.3:8b | ~6GB | 범용 | ⭐⭐⭐⭐ |
| Phi-4:14b | ~10GB | 추론/효율 | ⭐⭐⭐⭐ |
| Mistral:7b | ~5GB | 빠른 응답 | ⭐⭐⭐⭐ |
| Gemma 2:9b | ~7GB | 대화 | ⭐⭐⭐ |
요즘 핫한 모델은 DeepSeek-R1이에요. 추론 능력이 OpenAI o1급이라는 평가를 받고 있고, 8B 버전은 3060에서 쾌적하게 돌아갑니다.
텔레그램 봇에 연결해서 단톡방 농담봇 + 웹검색봇으로 활용할 계획이에요.
# Ollama로 간단하게
ollama pull deepseek-r1:8b # 추론용
ollama pull qwen2.5-coder:7b # 코딩용
ollama run deepseek-r1:8b
📝 교훈#
- GPU만 좋다고 되는 게 아니다 - RAM, 메인보드 등 전체 밸런스가 중요해요
- 와이프 설득은 PPT로 - 논리적 접근이 답입니다 ㅋㅋ
- H61은 16GB가 한계 - 하지만 디스크 캐싱으로 해결 가능!
- 문제는 해결책이 있다 - 보드 교체 없이도 방법은 있어요
🚀 앞으로의 계획#
- 백테스팅으로 최적 전략 찾기
- 로컬 LLM 텔레그램 봇 구축
- 수익 내서 투자금 회수 (제발… 🙏)
비슷한 고민 하시는 분들께 도움이 되셨으면 좋겠어요. RAM 부족하면 프리컴퓨트 데이터를 디스크에 캐싱하는 방법도 고려해보세요!
궁금한 점 있으시면 댓글로 남겨주세요!